Data Engineer Resume Examples, Templates & Writing Guide

Written by: Scale.jobs EditorialLast updated: May 1, 2026








Introduction
Create a compelling data engineer resume that showcases your expertise in building scalable data pipelines, designing warehouse architectures, and enabling reliable analytics at petabyte scale.
This guide walks you through every major section of a data engineer resume, with practical tips you can apply today.
- How to describe data pipeline architecture and orchestration experience with measurable reliability
- Strategies for showcasing data warehouse design using dimensional modeling and star schemas
- Techniques for quantifying data engineering impact through pipeline throughput and latency metrics
- Best practices for presenting ETL and ELT transformation experience at production scale
- Methods for highlighting data quality frameworks and governance initiatives on your resume
- How to demonstrate cost optimization in cloud data platform spending and resource management


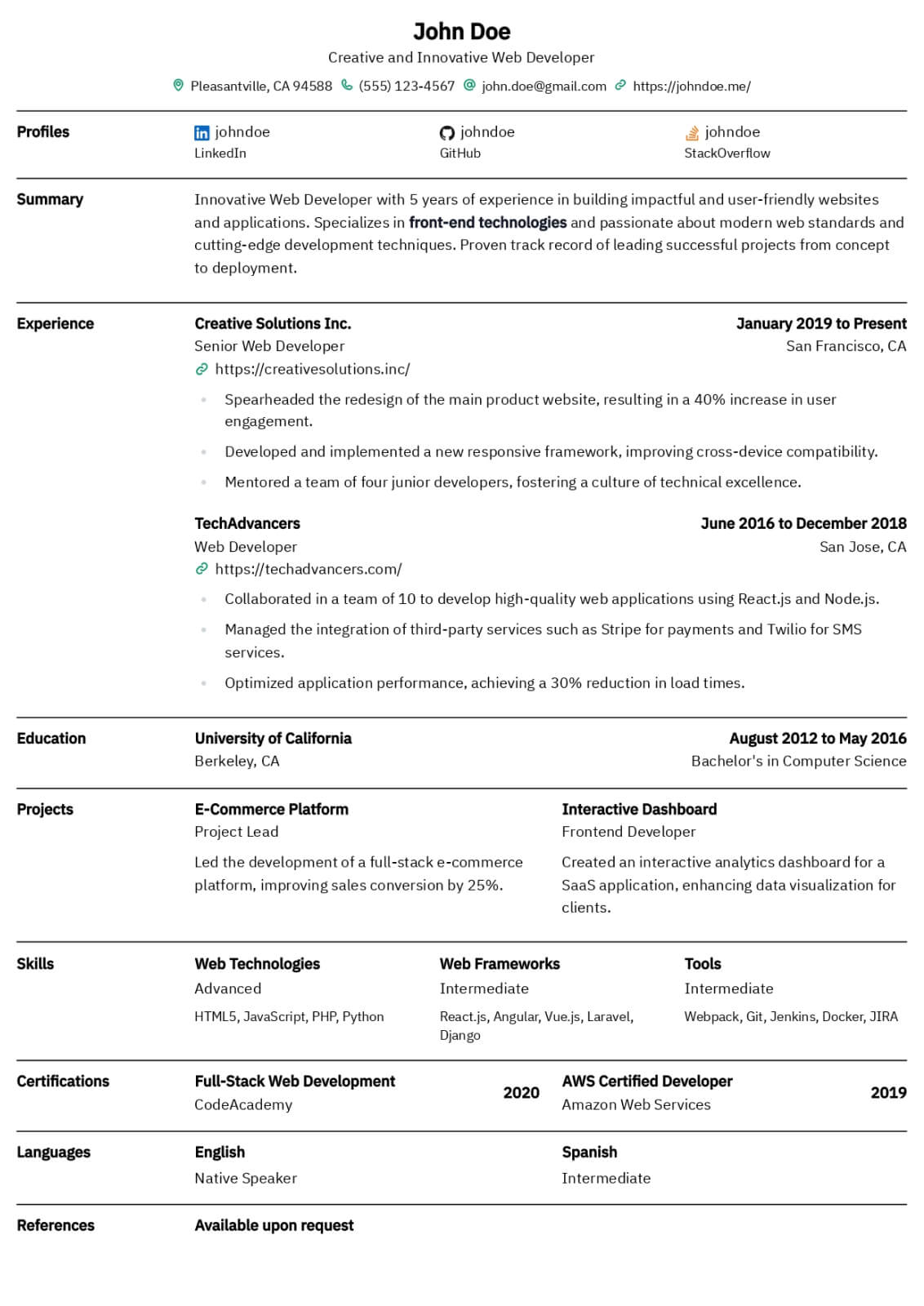
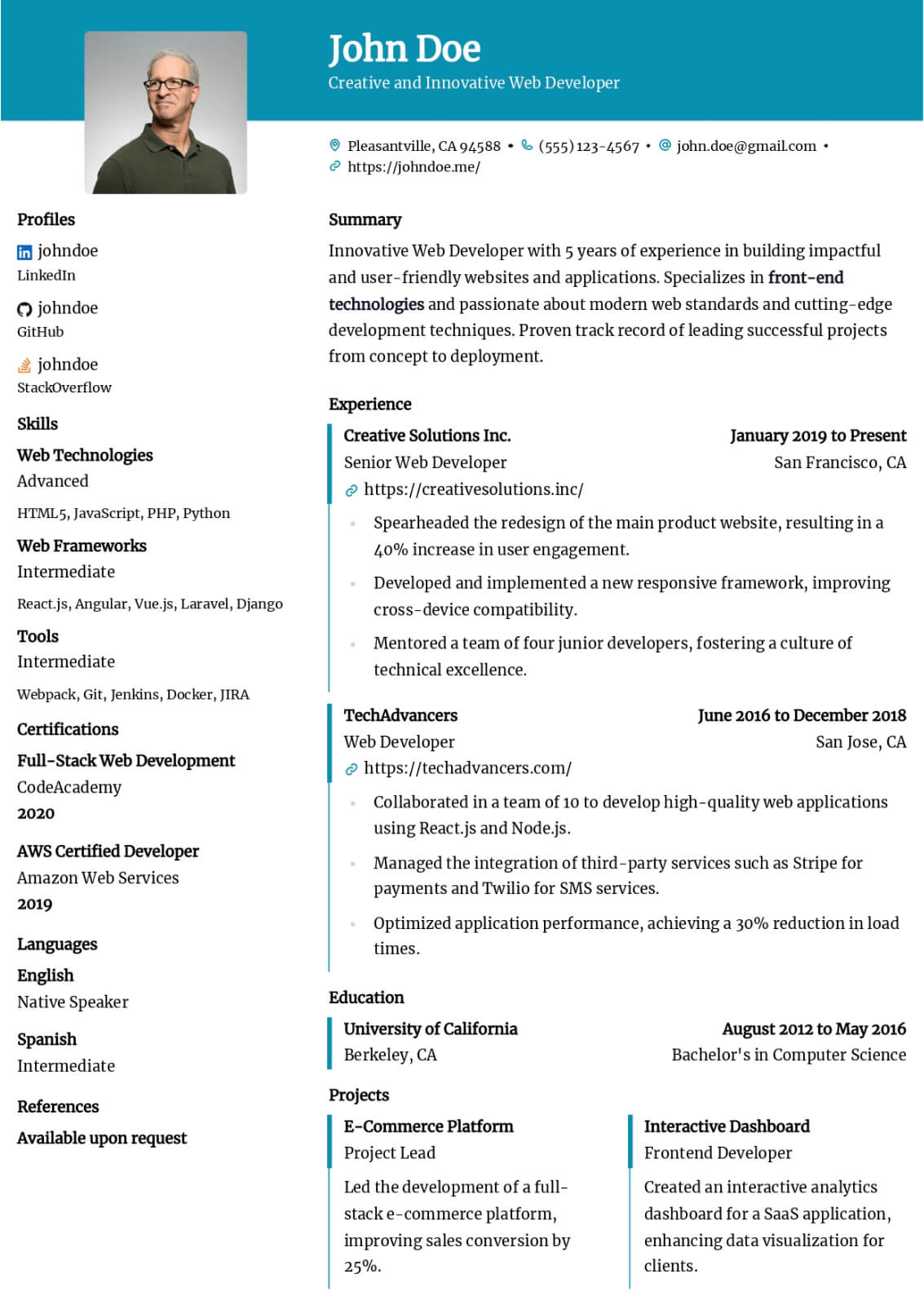
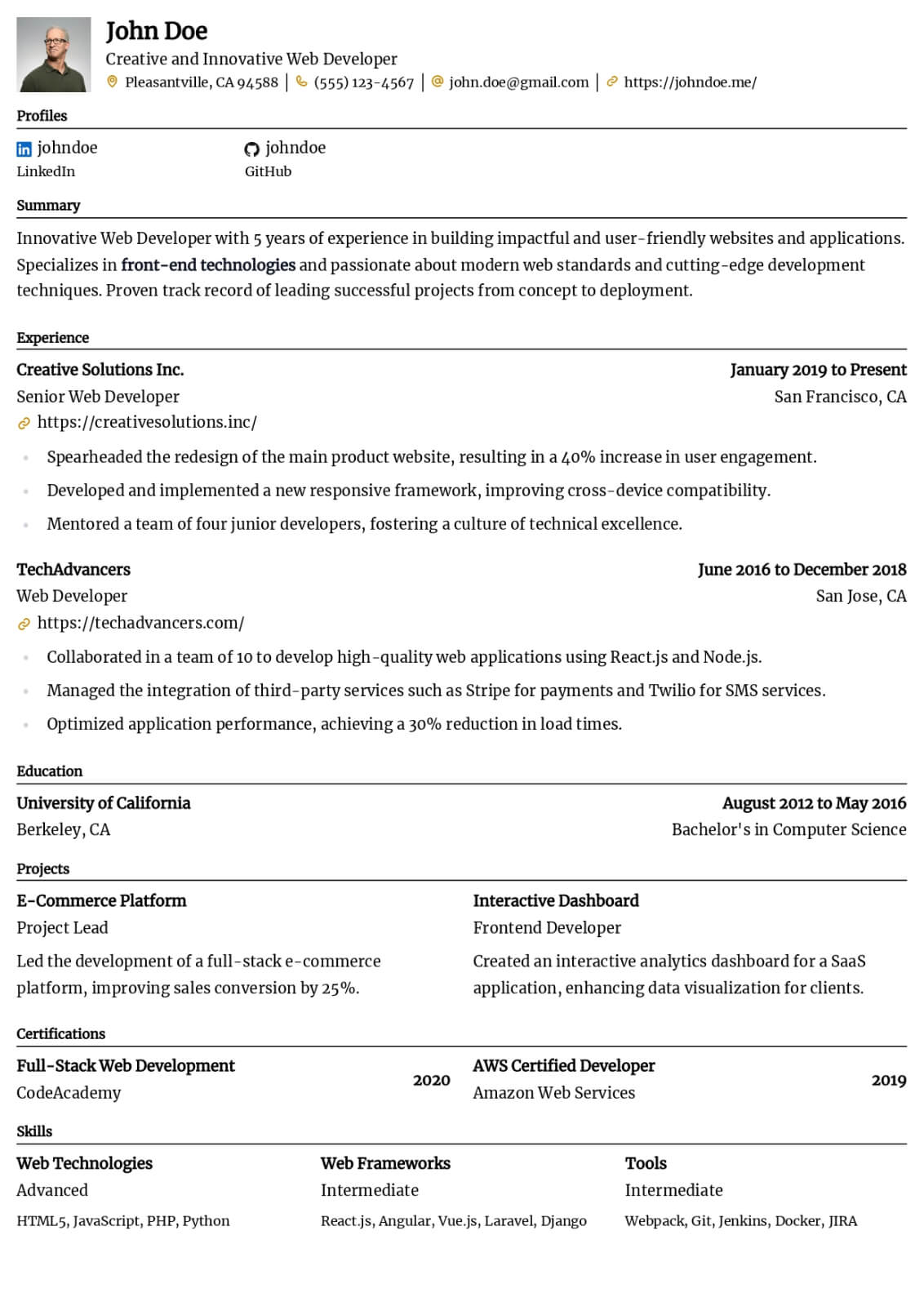
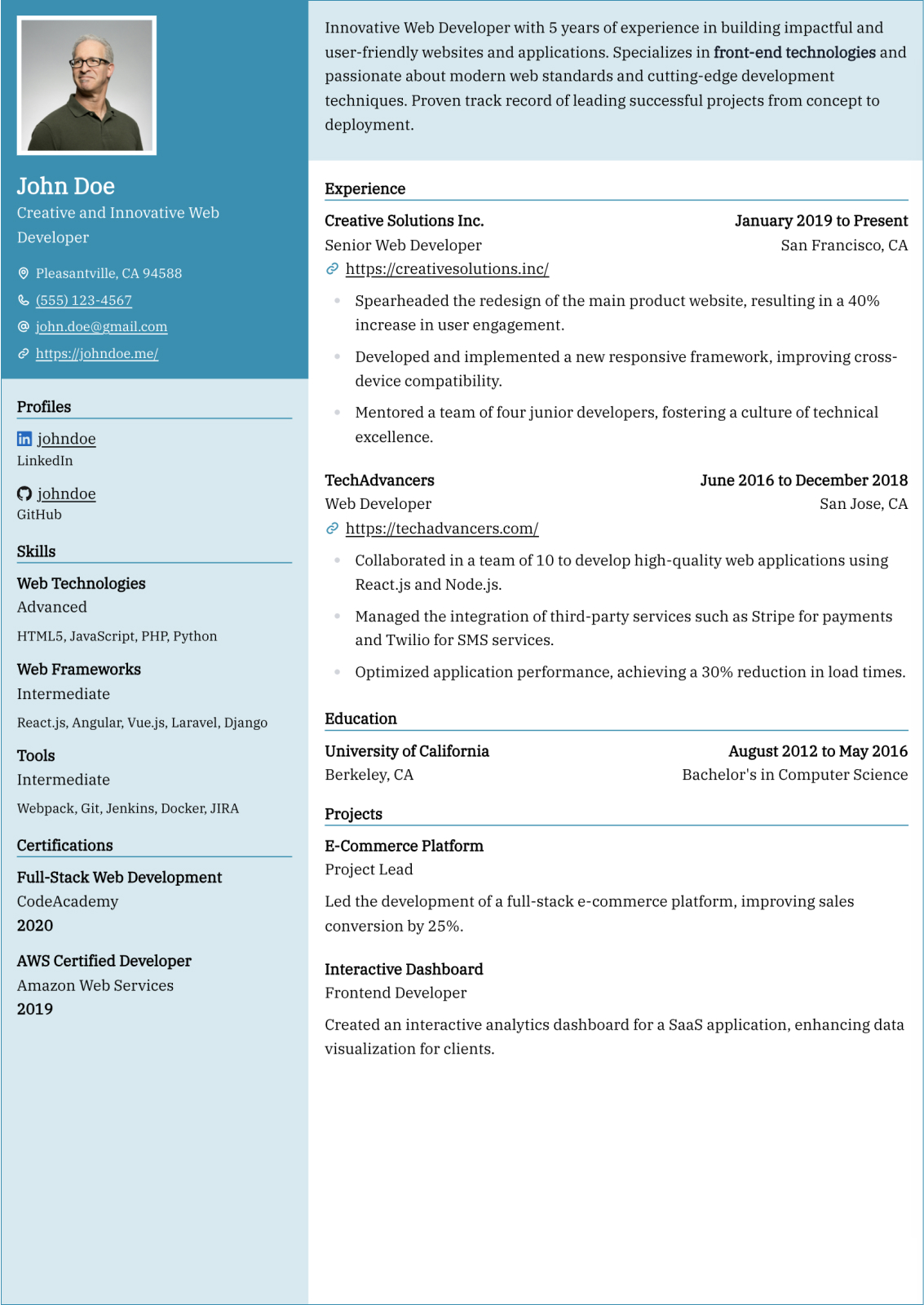

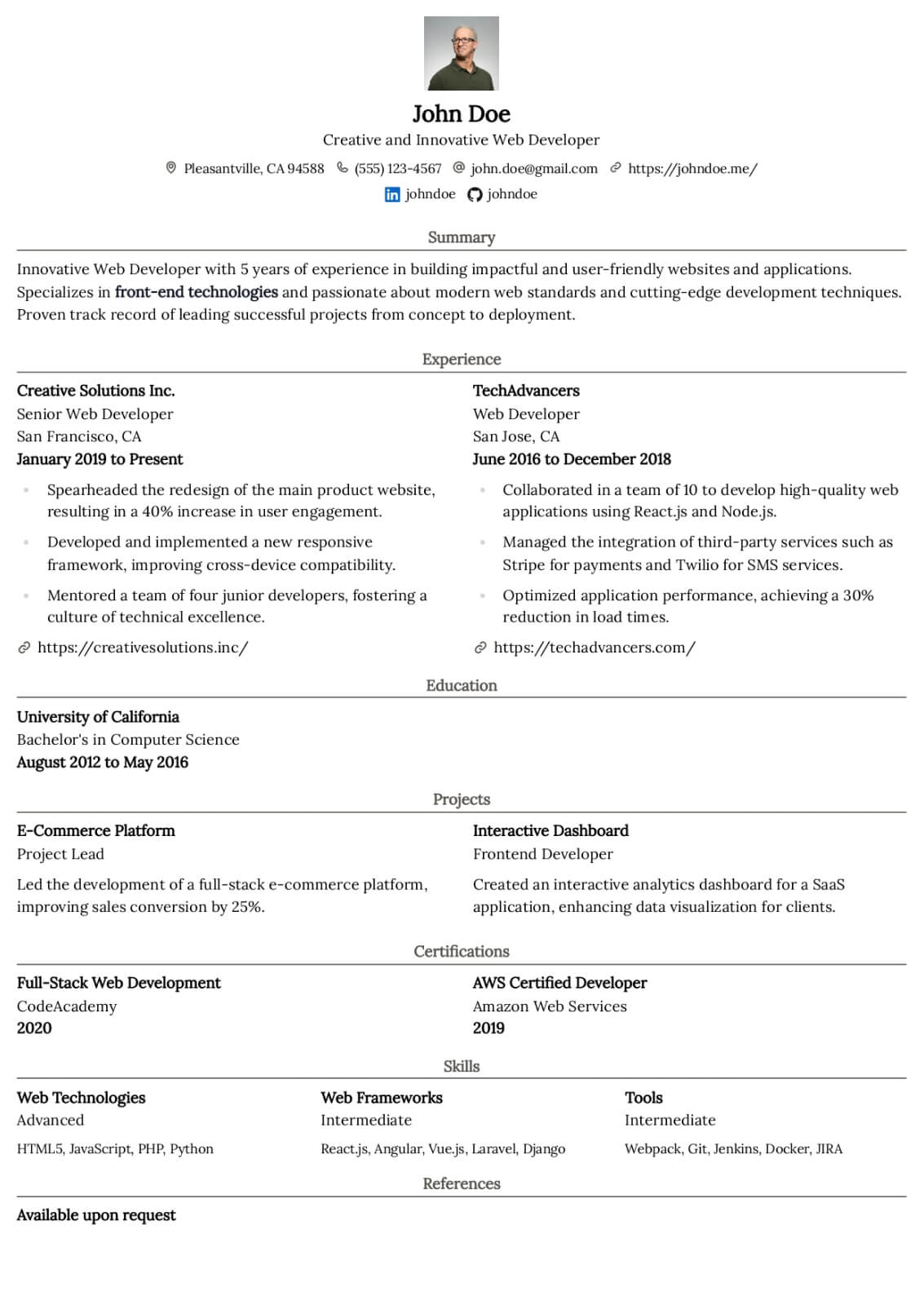

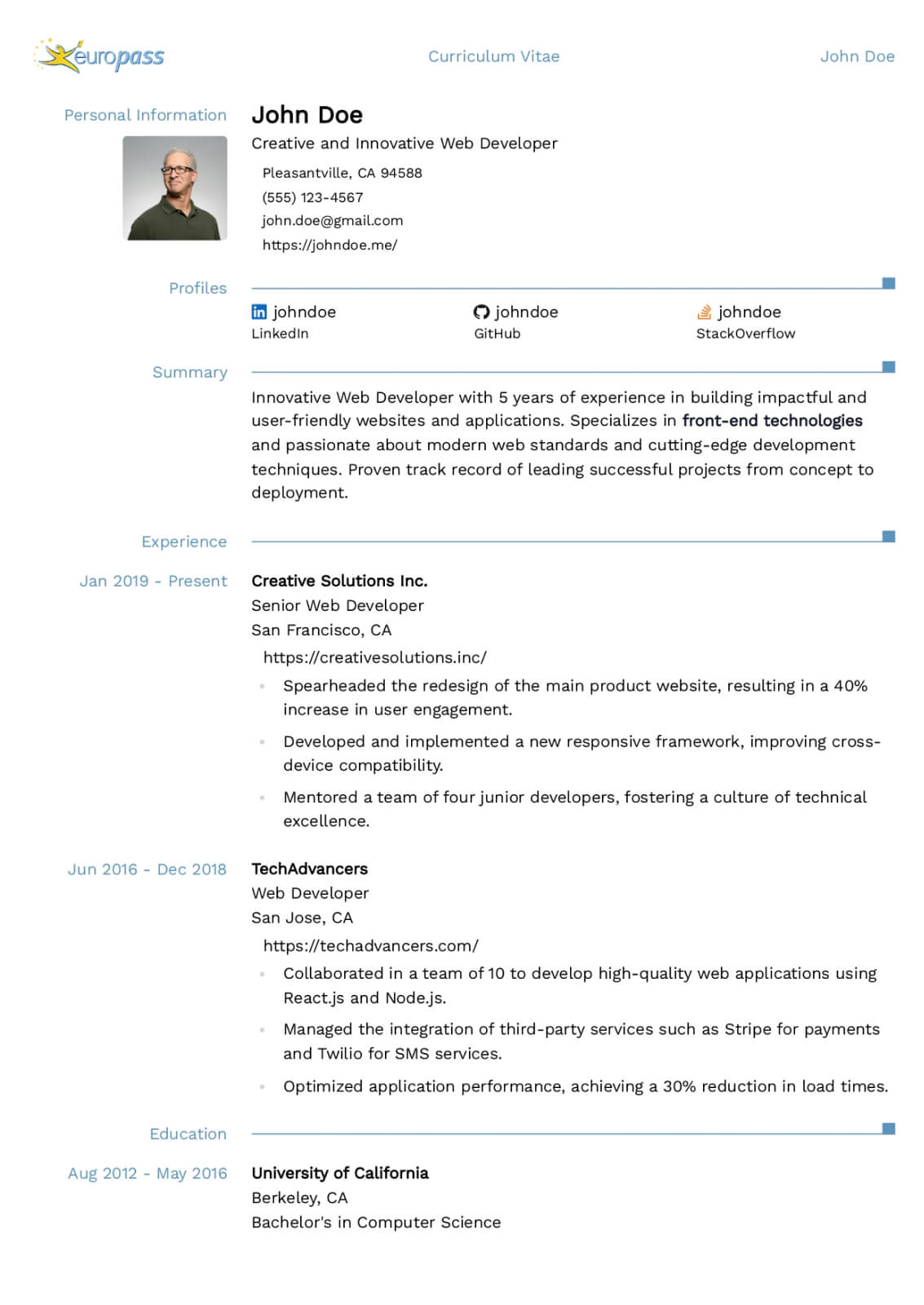


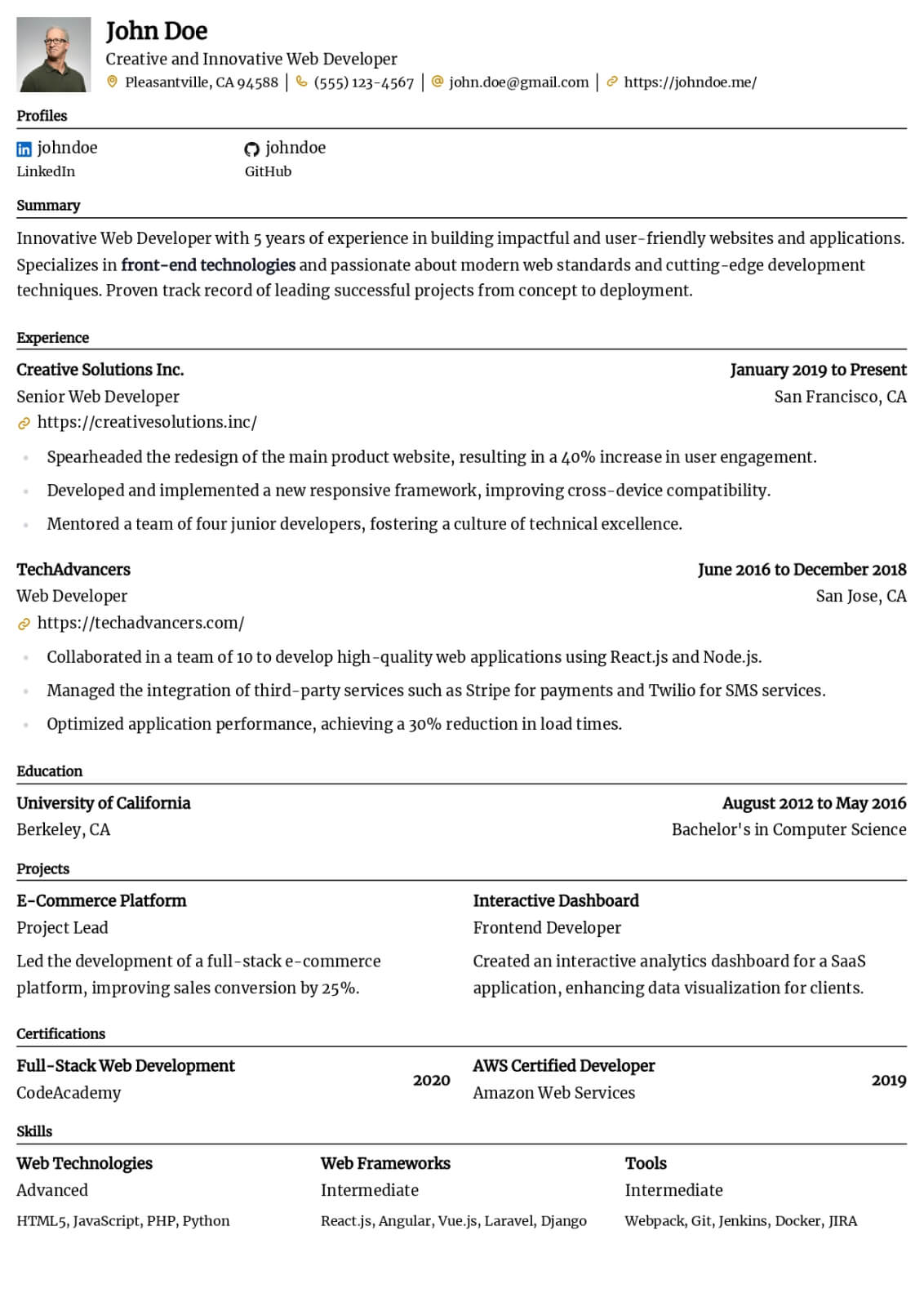
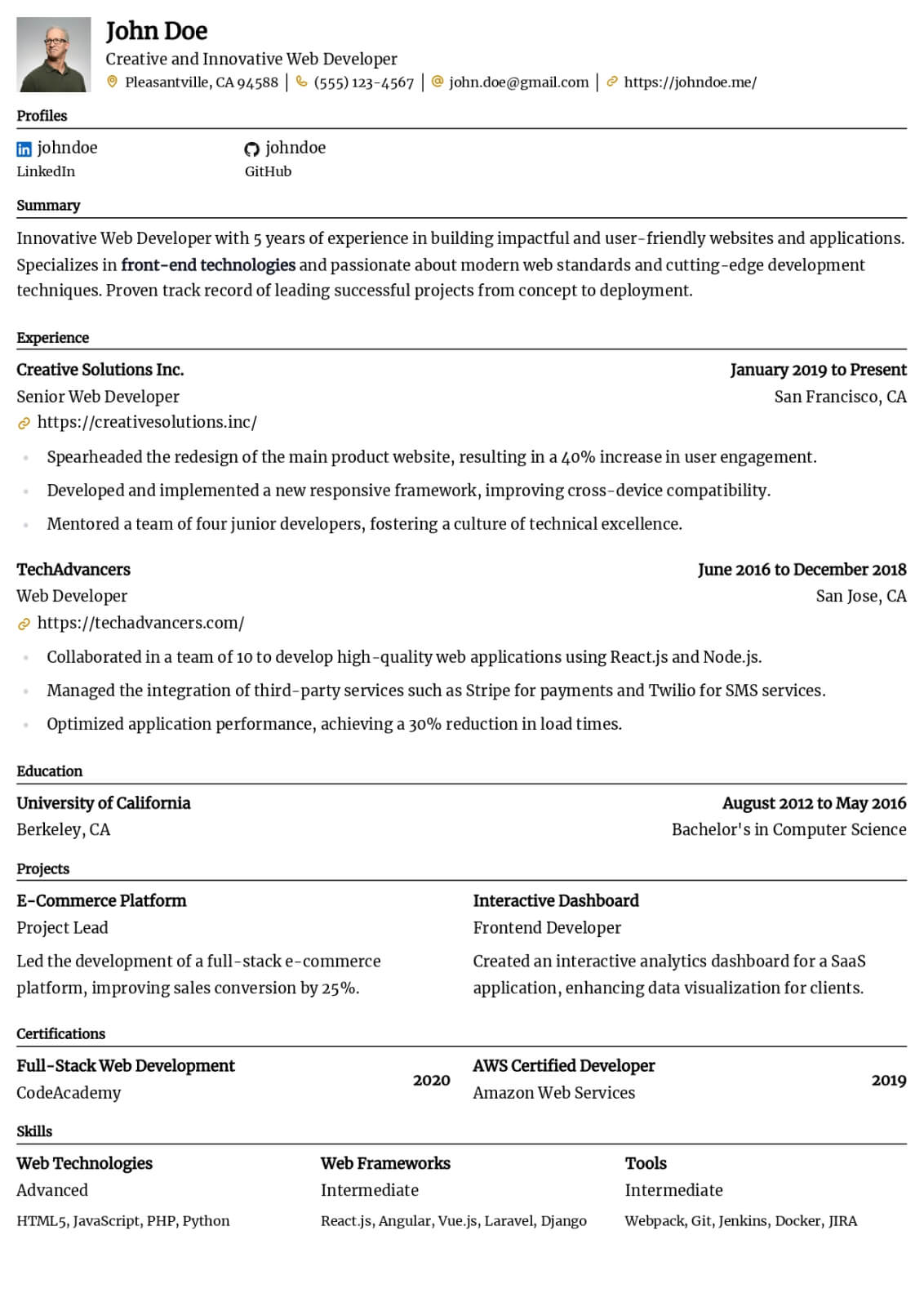
Data Engineer resume guide
Below, you will find section-by-section guidance for your data engineer resume — from your opening summary through skills and experience. Tailor every line to the job you want.
Professional Summary
Your professional summary should position you as a data engineer who builds and maintains the infrastructure that powers organizational decision-making. State your years of experience and primary technology stack including tools like Apache Spark, Airflow, dbt, and your preferred cloud data platform such as Snowflake, BigQuery, or Redshift. Reference the scale of data you have managed, whether that is terabytes processed daily or billions of records ingested monthly. Include a flagship achievement that connects your infrastructure work to business outcomes, such as designed a real-time data pipeline processing eight hundred million events daily that enabled the analytics team to reduce reporting latency from twenty-four hours to under five minutes. Mention your collaboration with data scientists, analysts, and business stakeholders to emphasize that your work enables downstream value creation. Close with the data challenges you seek, signaling readiness for the role.
Work Experience
Present each data engineering role with four to six bullet points demonstrating pipeline development, data modeling, and operational excellence. Open each bullet with action verbs like engineered, orchestrated, optimized, migrated, or automated. Connect actions to measurable results: built an Apache Spark pipeline on EMR that processed three terabytes of clickstream data daily, reducing data freshness from twelve hours to forty-five minutes while cutting compute costs by twenty-eight percent. Describe your data modeling contributions including schema design decisions, partitioning strategies, and query performance improvements. Highlight data quality work such as implementing validation frameworks that caught data anomalies before they reached downstream consumers. Show cross-functional impact by describing how your pipelines enabled specific analytics capabilities or machine learning model training workflows that the data science team depended on daily.
Technical Skills
Organize your data engineering skills into categories including programming languages, orchestration tools, processing frameworks, data stores, cloud platforms, and data quality tools. Under languages list Python, SQL, and Scala or Java as core competencies. For orchestration include Apache Airflow, Dagster, Prefect, or similar workflow management tools you operate in production. List processing frameworks like Apache Spark, Apache Flink, Apache Beam, or dbt that form the backbone of your transformation work. Under data stores include cloud warehouses like Snowflake, BigQuery, or Redshift alongside storage layers like Delta Lake, Apache Iceberg, or S3. Add cloud platform services specific to data engineering such as AWS Glue, Google Dataflow, or Azure Data Factory. Include data quality and governance tools like Great Expectations, Monte Carlo, or custom validation frameworks to demonstrate that you prioritize reliability in your data infrastructure.
Data Architecture & Pipeline Projects
A dedicated section highlighting significant data architecture projects demonstrates that you design systems rather than simply maintain existing ones. Describe two to three initiatives covering the business need, your architectural approach, technology choices, and quantified outcomes. For example, you might describe designing a lakehouse architecture on Delta Lake and Databricks that unified batch and streaming data processing, eliminating data silos across five business units and reducing total data platform costs by forty percent. Include details about data modeling methodologies like Kimball dimensional modeling or Data Vault approaches. Reference governance implementations such as data cataloging, lineage tracking, or access control policies that ensured data quality and compliance. This section is particularly impactful for mid-level and senior candidates seeking architecture-focused roles.
Certifications & Education
List data engineering certifications such as Databricks Certified Data Engineer Professional, AWS Data Analytics Specialty, Google Professional Data Engineer, or Snowflake SnowPro Core alongside the issuing organization and year earned. These certifications validate your ability to design and operate data infrastructure on platforms that employers rely on for their analytics workloads. In the education section include your degree, institution, and graduation year. Computer science, information systems, mathematics, or engineering degrees are common backgrounds for data engineers. Highlight relevant coursework in database systems, distributed computing, or data structures if you graduated recently. For experienced data engineers, position education below professional experience and let your pipeline portfolio and architecture achievements carry the primary weight of your candidacy.
Formatting & ATS Optimization
Use a clean single-column layout with standard section headings to ensure ATS compatibility. Embed technology keywords naturally within experience descriptions, using exact tool names like Apache Airflow rather than generic terms like workflow orchestration tool. Include both abbreviated and full forms where relevant, such as ETL and extract-transform-load, to capture keyword variations across different ATS configurations. Quantify your achievements with specific data volumes, processing speeds, and cost figures to create scannable, high-impact bullet points. Save as PDF and keep your resume to one or two pages depending on experience depth. Include links to your GitHub profile or technical blog where reviewers can explore your data engineering projects and SQL or pipeline code quality.
Resume layout and formatting
Use a clean, single-column layout with clear section headings and plenty of white space. Lead with technical strengths such as Python & SQL, Apache Spark & PySpark, Apache Airflow / Dagster, dbt (Data Build Tool), Snowflake / BigQuery / Redshift, AWS / GCP / Azure Data Services, then reinforce interpersonal strengths like Analytical Problem Solving, Cross-Team Collaboration with Analysts & Scientists, Documentation & Technical Writing, Prioritization of Pipeline Reliability. Keep fonts standard (e.g., Arial or Calibri) at 10–12pt body size so your resume stays ATS-friendly and easy to scan.
Key takeaways
- Lead your summary with data volume metrics and primary pipeline technologies
- Quantify pipeline throughput, latency reduction, and cost savings in every bullet
- Include data architecture projects that demonstrate system design beyond task execution
- Organize skills by data engineering domain for clear and structured presentation
- List cloud data platform certifications prominently as they validate specialized expertise
- Link to GitHub or technical blogs to showcase pipeline code and architectural thinking
Build your Data Engineer resume with Scale
Lead your summary with data volume metrics and primary pipeline technologies
Use This Template
Professional Templates That Make You Stand Out
Browse modern, ATS-friendly resume designs crafted to impress recruiters. Customize any template and download it as a Word or PDF file.
Listen What Our Users Have to Say

Rohan Sen
I am very happy with the team's quick turnaround time - any query is responded at utmost priority. Shoutout to my client manager, Anub Biju - very helpful.

Gael L
Service and communication is great, cover letters are non-ai sounding and well tailored. Just have a lot of communication and review with your staff!

Jonathan Parry
Wow - don't tell your peers! Wow, I can't recommend scale.jobs enough - it's so good I am not sharing with my peers. Applications at scale that get through filters. Thank you!

Cynthia Zhu
Great service! The scale.jobs team was very responsible and managed to apply tons of jobs for me in a very tight deadline to help me secure interviews quickly. Highly recommend to anyone who needs help applying to jobs!

Yash Yenugu
Save your fingers. Saved me from a thumb cramp because we're expected to effortlessly apply to jobs during these times.

Cian O'Driscoll
Clever service. Takes the hard effort out of applying for jobs with an intuitive dashboard and attention to detail. A great asset to job seekers. :-)
Frequently asked questions
What should a data engineer resume focus on in 2026?
Modern data engineer resumes should emphasize cloud-native pipeline development, real-time streaming architecture, data quality automation, and cost-efficient warehouse design. Highlight experience with tools like Spark, Airflow, dbt, and cloud platforms such as Snowflake or BigQuery. Include quantified metrics about data volumes processed, pipeline reliability SLAs, and cost optimizations to demonstrate operational maturity.
How do I quantify data engineering achievements on my resume?
Measure pipeline throughput in records or terabytes processed per day, latency reductions with before-and-after comparisons, data freshness improvements, and infrastructure cost savings as percentages or dollar amounts. For example, state that you reduced pipeline execution time from six hours to forty minutes while cutting monthly Spark cluster costs by thirty-two percent. Concrete numbers make your contributions tangible and comparable.
Is Python or SQL more important for data engineering roles?
Both are essential and you should demonstrate strong proficiency in each. SQL is fundamental for data transformation, modeling, and query optimization in warehouse environments. Python is critical for pipeline orchestration, custom transformation logic, and integration with ML workflows. Most data engineering interviews test both skills heavily, so position them as co-equal core competencies on your resume.
Should I include data modeling experience on my resume?
Data modeling expertise is highly valued and should be prominently featured. Describe your experience with dimensional modeling methodologies like Kimball star schemas, Data Vault, or activity schemas. Explain specific modeling decisions and their impact on query performance and analyst productivity. Data engineers who can design efficient, maintainable schemas are more valuable than those who only build pipelines on top of existing models.
How important are certifications for data engineering roles?
Certifications in cloud data platforms like Databricks, Snowflake, or AWS Data Analytics validate platform-specific expertise that employers rely on. They carry meaningful weight when competing against equally experienced candidates. However, certifications complement rather than replace hands-on experience. List them prominently on your resume but ensure your experience section demonstrates practical application of the certified skills.
How do I describe real-time streaming experience on my resume?
Specify the streaming technology such as Apache Kafka, Flink, or Kinesis, the data volume processed per second, and the business use case enabled. For example, state that you built a Kafka Streams pipeline processing two hundred thousand events per second for real-time fraud detection. Include details about exactly-once semantics, consumer group management, or schema evolution to demonstrate deep operational knowledge.
Related Resume Guides
Data Scientist
Build a compelling data scientist resume that demonstrates your statistical modeling expertise, machine learning proficiency, and ability to translate complex data insights into measurable business outcomes.
Data Analyst
Build an effective data analyst resume that demonstrates your proficiency in SQL, data visualization, and translating complex datasets into actionable insights that drive strategic business decisions.
Database Administrator
Craft a compelling database administrator resume that highlights your expertise in performance tuning, data integrity, and enterprise-scale database management to land interviews at top organizations.
Software Engineer
Craft a compelling software engineer resume that highlights your technical depth, system design expertise, and measurable contributions to production software used by millions of users worldwide.
Cloud Engineer
Create a powerful cloud engineer resume that demonstrates your expertise in designing, deploying, and managing cloud infrastructure across AWS, Azure, or GCP with reliability and cost efficiency.