Machine Learning Engineer Resume Examples, Templates & Writing Guide

Written by: Scale.jobs EditorialLast updated: May 1, 2026








Introduction
Build a powerful machine learning engineer resume that highlights your expertise in model training, MLOps infrastructure, production deployment, and building scalable ML systems that deliver measurable business value.
This guide walks you through every major section of a machine learning engineer resume, with practical tips you can apply today.
- How to showcase end-to-end ML pipeline experience from data preprocessing to production serving
- Strategies for presenting model training and optimization with measurable performance improvements
- Techniques for quantifying ML engineering impact through latency, throughput, and accuracy metrics
- Best practices for describing MLOps infrastructure including CI/CD for models and monitoring
- Methods for highlighting research contributions, patents, and published ML papers
- How to balance deep learning expertise with production engineering skills on your resume


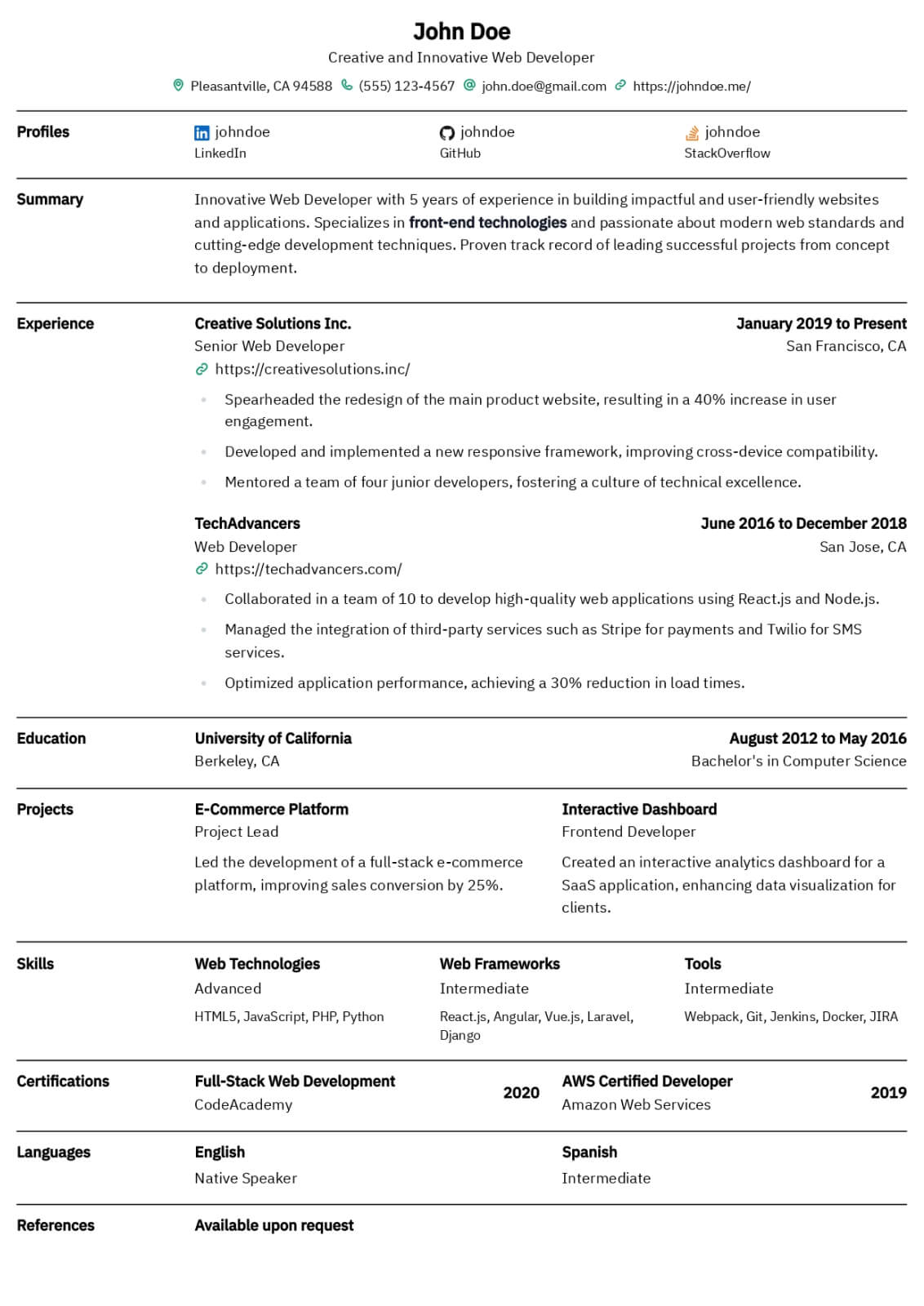
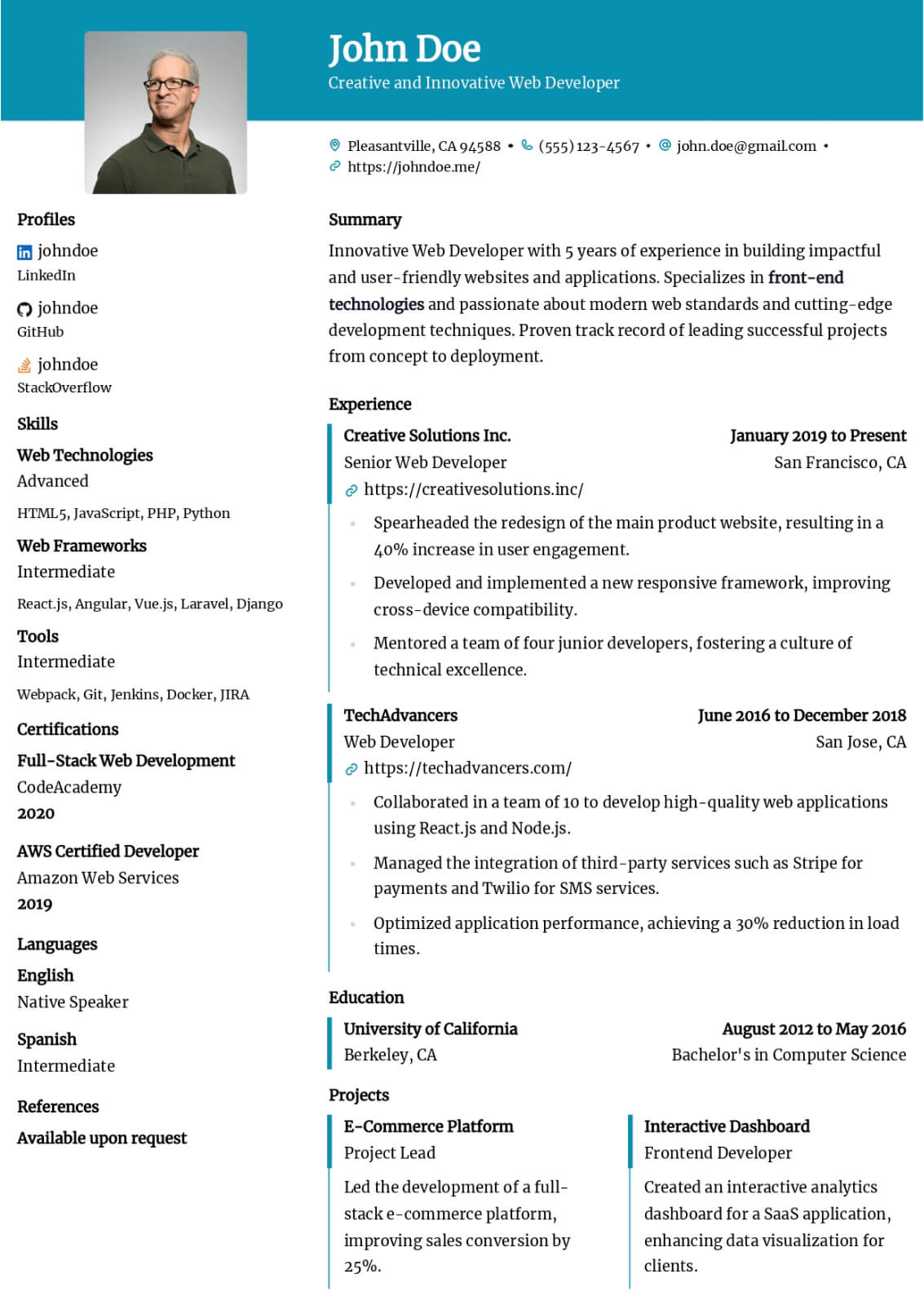
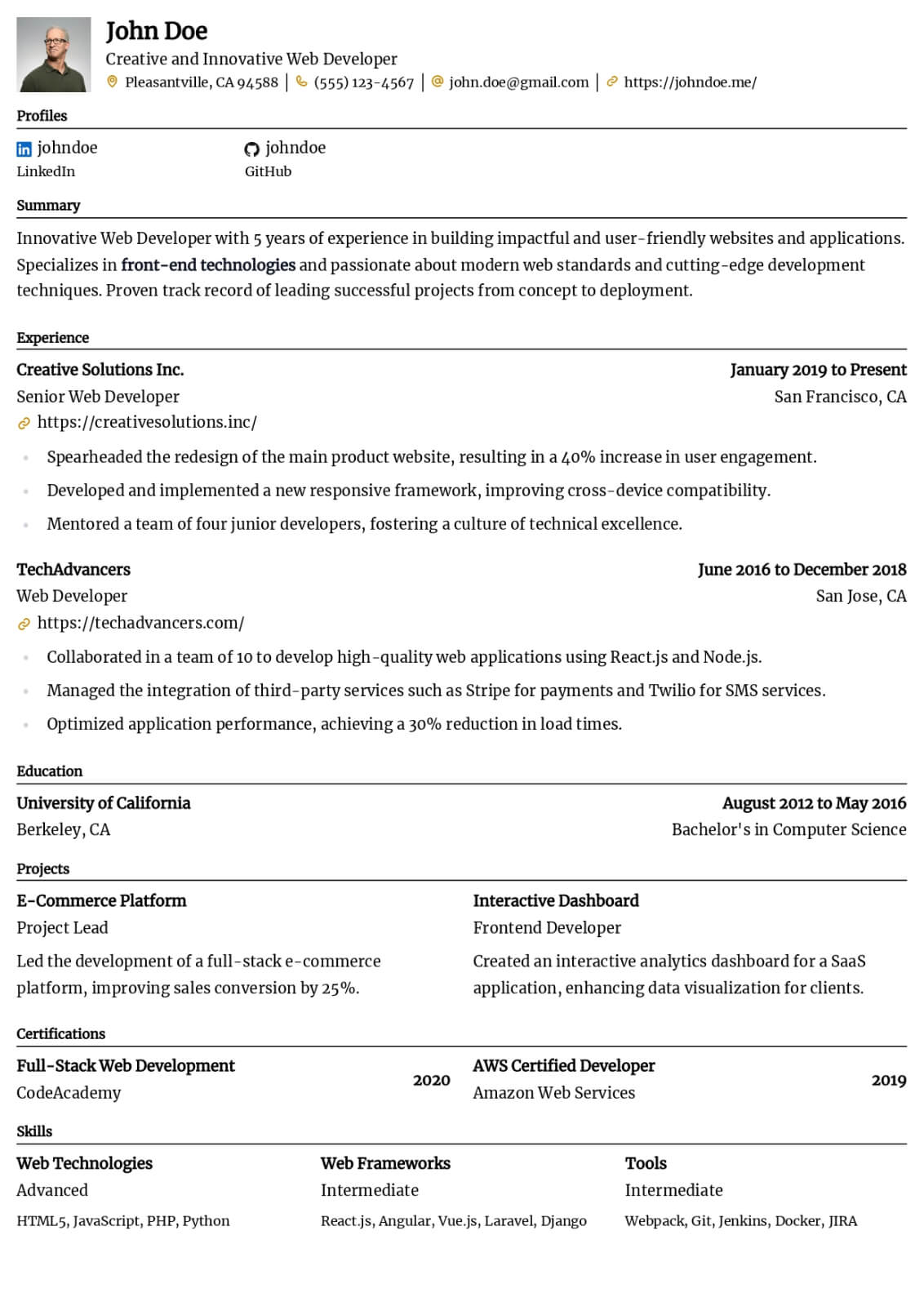
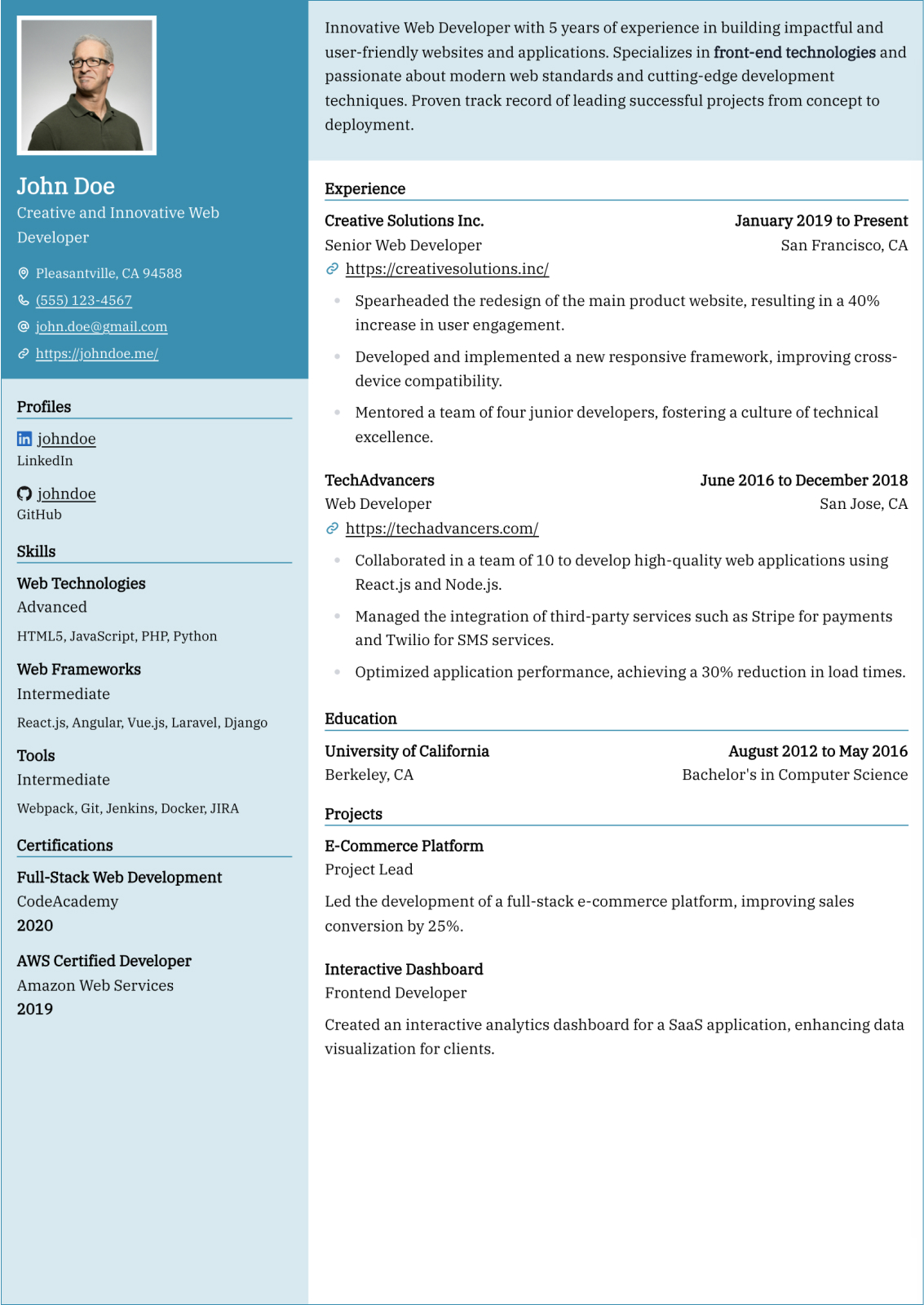

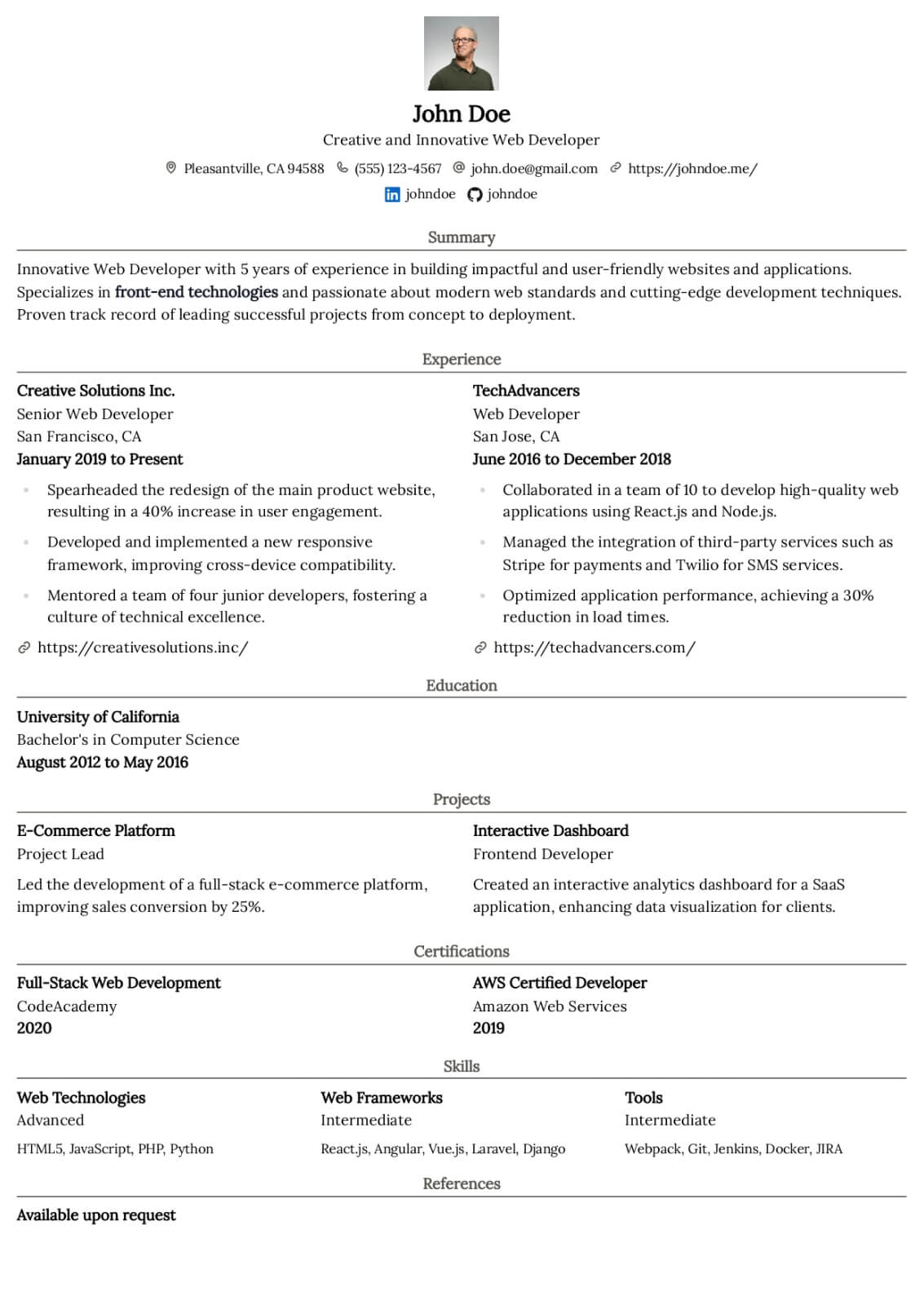

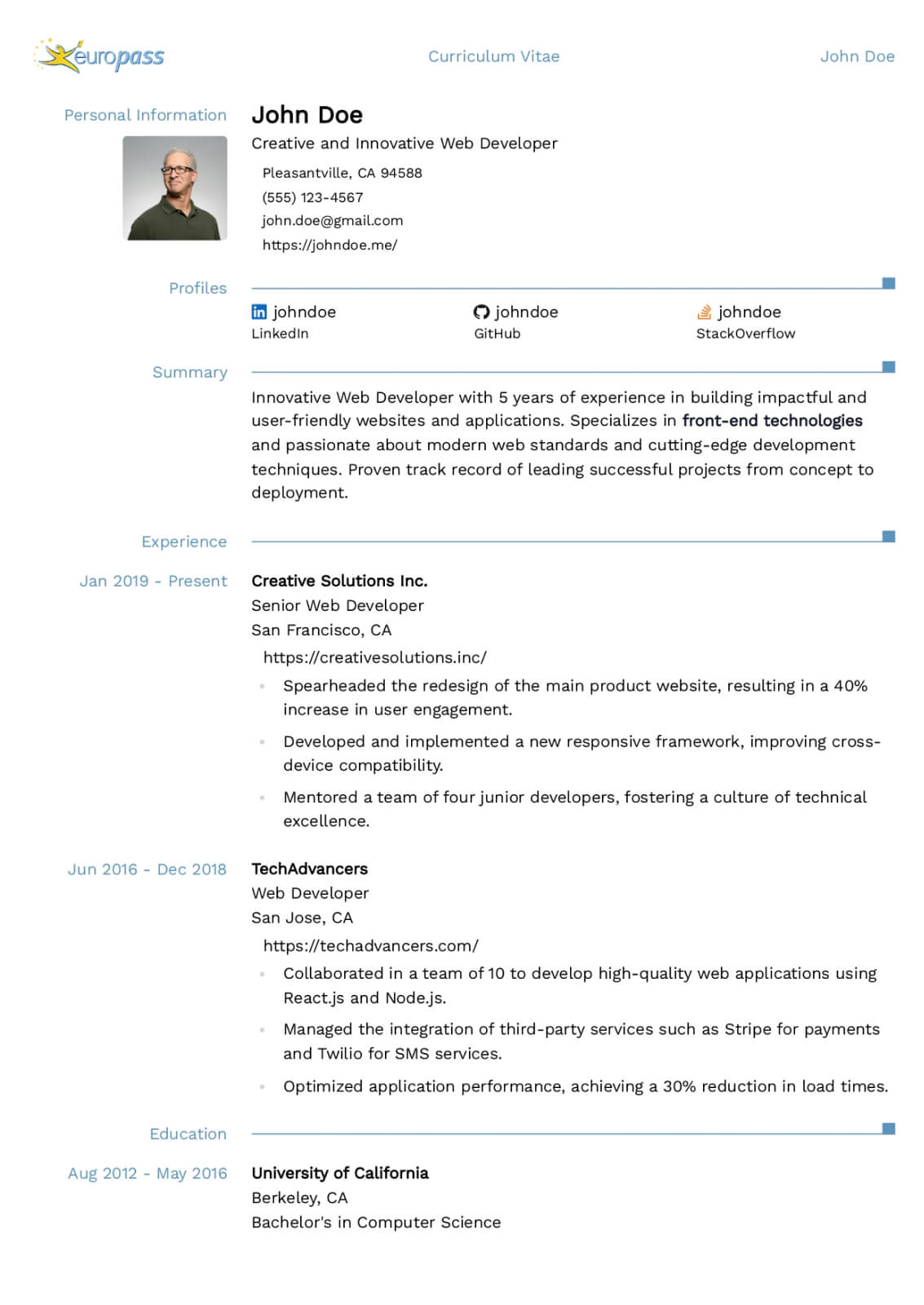


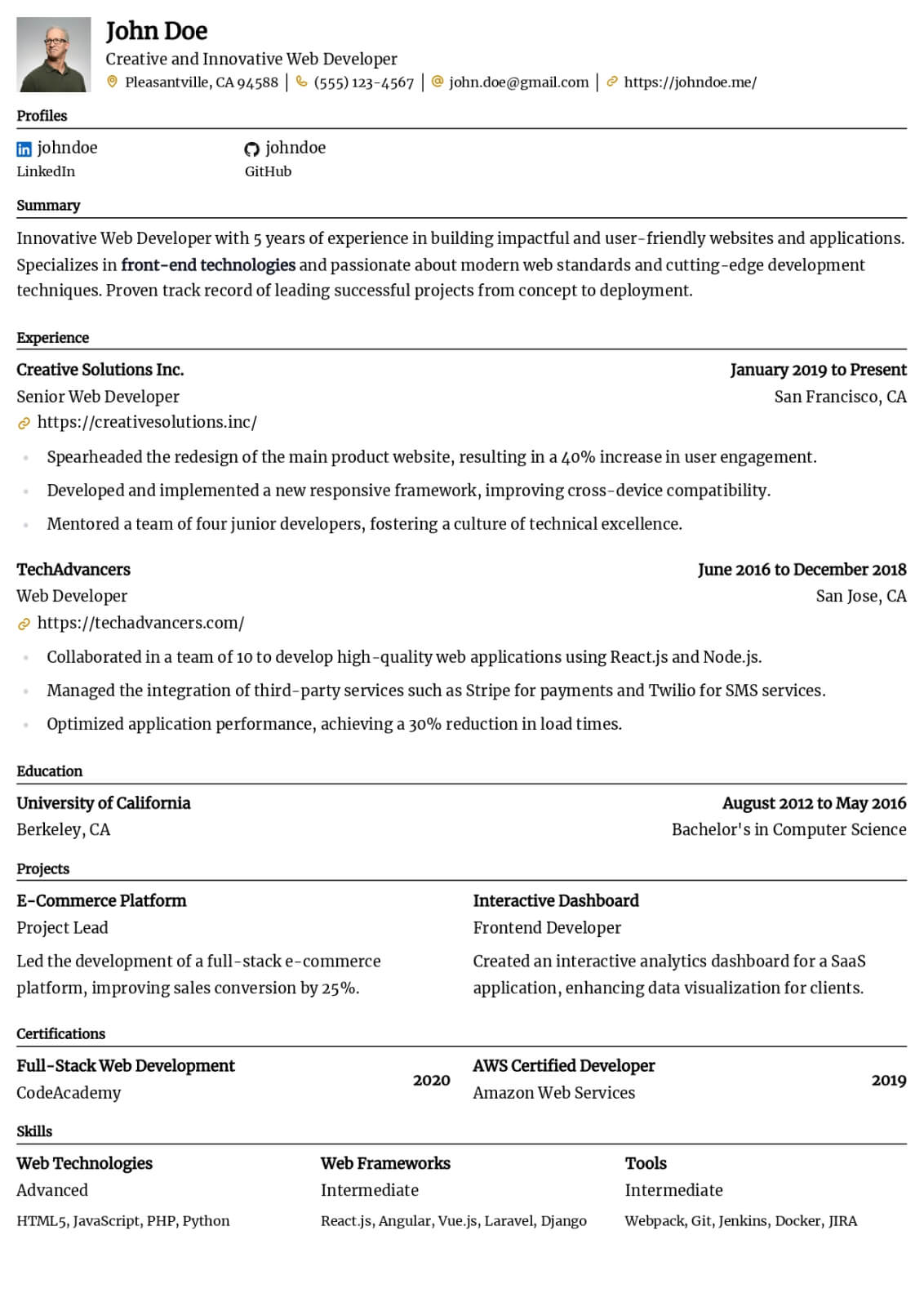
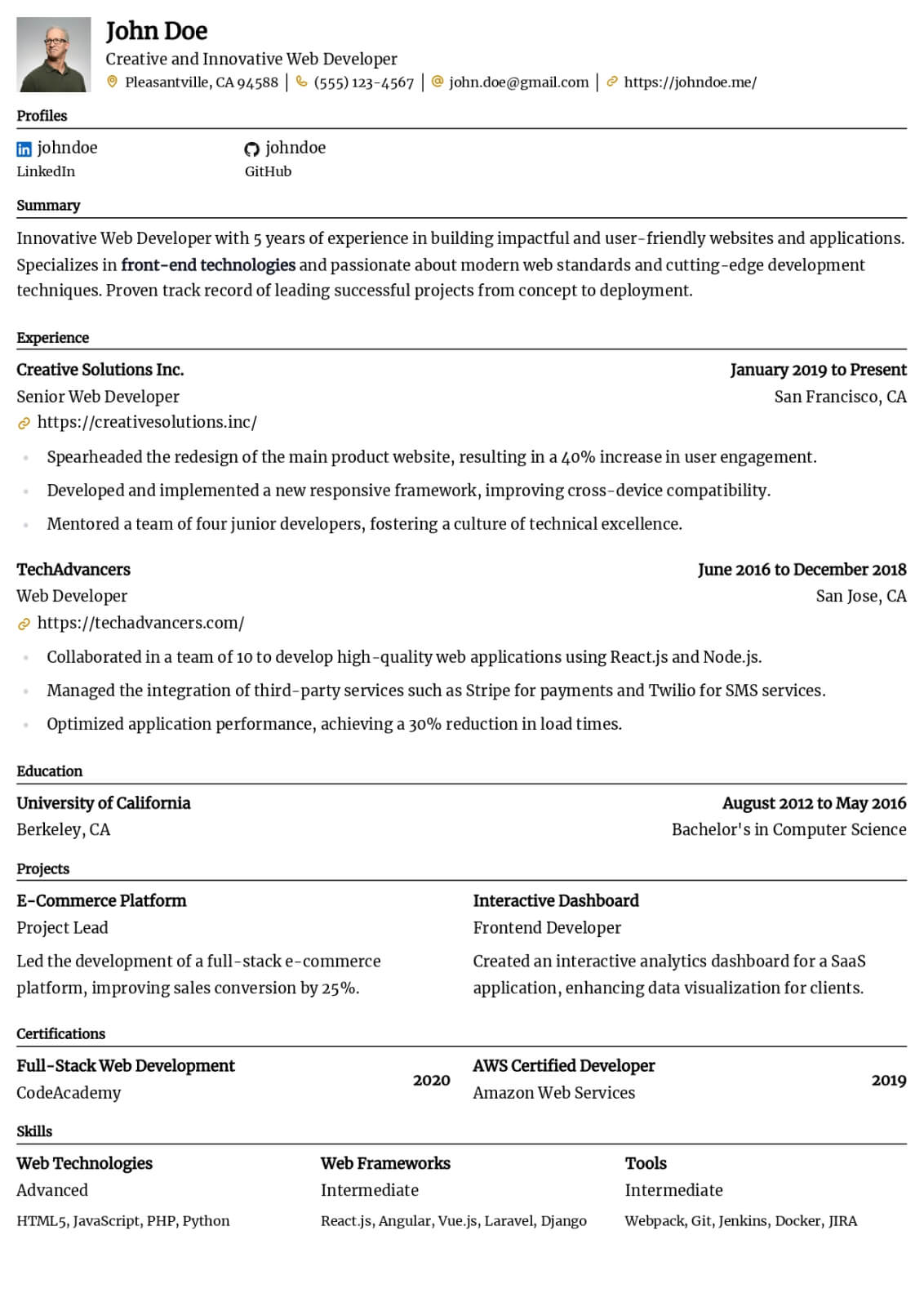
Machine Learning Engineer resume guide
Below, you will find section-by-section guidance for your machine learning engineer resume — from your opening summary through skills and experience. Tailor every line to the job you want.
Professional Summary
Your professional summary should establish you as an engineer who bridges the gap between ML research and production systems. State your years of experience and primary specialization areas such as computer vision, NLP, recommendation systems, or generative AI. Name your core frameworks including PyTorch, TensorFlow, JAX, or Hugging Face Transformers alongside deployment tools like TorchServe, Triton Inference Server, or SageMaker. Reference the scale of ML systems you have operated, whether that means models serving millions of predictions daily or training pipelines processing terabytes of data. Include a flagship achievement such as designed and deployed a real-time recommendation model that increased click-through rates by twenty-three percent across forty million daily active users. Mention your collaboration with data scientists on model research and software engineers on production integration to position yourself as a cross-functional connector.
Work Experience
Present each ML engineering role with four to six bullet points covering model development, infrastructure, deployment, and monitoring. Lead each bullet with action verbs like trained, optimized, deployed, scaled, or instrumented. Attach quantified outcomes to every achievement: trained a transformer-based ranking model using distributed training across sixteen GPUs, reducing training time from seventy-two hours to eight hours while improving nDCG by twelve percent. Describe your MLOps contributions including automated training pipelines, model versioning with tools like MLflow or Weights and Biases, and A/B testing frameworks for model comparison. Highlight production engineering work such as serving infrastructure optimization, model compression techniques, and latency reduction for real-time inference endpoints. Include collaboration examples showing how you worked with research teams to translate prototypes into production-ready systems.
Technical Skills
Organize ML engineering skills into categories including frameworks, infrastructure, serving and deployment, data processing, and cloud ML services. Under frameworks list PyTorch, TensorFlow, JAX, Hugging Face, scikit-learn, and XGBoost with specialization indicators for areas like computer vision or NLP. For infrastructure include distributed training tools like DeepSpeed, Horovod, or PyTorch Distributed along with experiment tracking platforms like MLflow and Weights and Biases. Under serving list TorchServe, TensorFlow Serving, Triton Inference Server, and ONNX Runtime along with containerization with Docker and Kubernetes. Add data processing tools like Apache Spark, Ray, and feature store platforms such as Feast or Tecton. Include cloud ML services like AWS SageMaker, Google Vertex AI, or Azure ML Studio. List programming languages with Python as primary and C++ or Rust if you write custom operators or high-performance inference code.
MLOps & Production Systems
A dedicated MLOps section demonstrates that you understand the operational complexity of maintaining ML systems in production, which is the core differentiator between ML engineers and research scientists. Describe two to three significant MLOps initiatives including the problem, your engineering approach, and the operational outcomes achieved. For example, you might describe building an automated retraining pipeline triggered by data drift detection that retrained and deployed updated models within four hours, maintaining prediction accuracy above a defined threshold without manual intervention. Include model monitoring implementations that track prediction quality, data distribution shifts, and serving latency in production. Describe feature store architectures, model registries, and deployment strategies like shadow deployments or canary rollouts that demonstrate operational sophistication. This section carries particular weight for senior roles focused on ML platform engineering.
Research & Publications
Include published papers, conference presentations, patents, or significant open-source contributions that demonstrate your technical depth and ability to push the field forward. For each entry provide the title, venue, year, and a brief description of the contribution and its impact. Reference papers published at venues like NeurIPS, ICML, AAAI, or industry-specific conferences. Include patents granted or filed that relate to your ML engineering work. Open-source contributions to major ML frameworks or tools are equally valued, especially pull requests that introduced new features, fixed performance bottlenecks, or improved documentation. For candidates without formal publications, Kaggle competition results with top rankings, technical blog posts, or conference talks demonstrate equivalent intellectual curiosity and community engagement.
Layout & ATS Optimization
ML engineer resumes should use a clean single-column format that accommodates both technical depth and ATS parsing requirements. Embed framework names exactly as they appear in the job posting, for example writing PyTorch rather than deep learning framework and Hugging Face Transformers rather than NLP library. Include both acronyms and full forms such as NLP and natural language processing to capture keyword variations. For ML engineering roles at research-oriented companies, a two-page resume is acceptable to accommodate publications and detailed project descriptions. Save as PDF and include links to your Google Scholar profile, GitHub, published papers, or personal research blog. Test your resume with ATS parsing tools to confirm accurate extraction of all sections and technical terminology.
Resume layout and formatting
Use a clean, single-column layout with clear section headings and plenty of white space. Lead with technical strengths such as PyTorch / TensorFlow / JAX, Hugging Face Transformers & Diffusers, Distributed Training (DeepSpeed, Horovod), MLflow / Weights & Biases, Model Serving (TorchServe, Triton, ONNX), Python & C++ for ML, then reinforce interpersonal strengths like Research-to-Production Translation, Cross-Team Collaboration, Technical Documentation, Experimental Rigor. Keep fonts standard (e.g., Arial or Calibri) at 10–12pt body size so your resume stays ATS-friendly and easy to scan.
Key takeaways
- Lead with your ML specialization and production-scale deployment achievements
- Quantify model performance improvements alongside business impact metrics
- Include MLOps infrastructure work that demonstrates operational engineering maturity
- Showcase research publications or open-source contributions to signal technical depth
- Organize skills by ML engineering domain rather than a flat keyword list
- Link to published papers, GitHub repositories, and research profiles for deeper review
Build your Machine Learning Engineer resume with Scale
Lead with your ML specialization and production-scale deployment achievements
Use This Template
Professional Templates That Make You Stand Out
Browse modern, ATS-friendly resume designs crafted to impress recruiters. Customize any template and download it as a Word or PDF file.
Listen What Our Users Have to Say

Rohan Sen
I am very happy with the team's quick turnaround time - any query is responded at utmost priority. Shoutout to my client manager, Anub Biju - very helpful.

Gael L
Service and communication is great, cover letters are non-ai sounding and well tailored. Just have a lot of communication and review with your staff!

Jonathan Parry
Wow - don't tell your peers! Wow, I can't recommend scale.jobs enough - it's so good I am not sharing with my peers. Applications at scale that get through filters. Thank you!

Cynthia Zhu
Great service! The scale.jobs team was very responsible and managed to apply tons of jobs for me in a very tight deadline to help me secure interviews quickly. Highly recommend to anyone who needs help applying to jobs!

Yash Yenugu
Save your fingers. Saved me from a thumb cramp because we're expected to effortlessly apply to jobs during these times.

Cian O'Driscoll
Clever service. Takes the hard effort out of applying for jobs with an intuitive dashboard and attention to detail. A great asset to job seekers. :-)
Frequently asked questions
What distinguishes an ML engineer resume from a data scientist resume?
ML engineer resumes emphasize production systems, model deployment infrastructure, serving optimization, and MLOps pipelines. Data scientist resumes focus more on statistical analysis, experiment design, and insight generation. ML engineers should highlight distributed training, model compression, and real-time inference capabilities that demonstrate their engineering focus on operationalizing models at scale.
How do I showcase model deployment experience on my resume?
Describe the serving infrastructure you built or managed, the prediction throughput achieved, and the latency constraints you met. For example, state that you deployed a real-time recommendation model on Triton Inference Server handling ten thousand predictions per second at sub-twenty-millisecond latency. Include details about containerization, scaling policies, and monitoring that demonstrate end-to-end production ownership.
Is a PhD required for machine learning engineering roles?
A PhD is valued at research-focused organizations but is not required for most industry ML engineering positions. Many ML engineers hold masters or bachelors degrees combined with strong practical experience and published work. Emphasize production deployment experience, scalable system design, and measurable business impact on your resume. Hands-on MLOps expertise often matters more than academic credentials for engineering-focused roles.
How important are Kaggle competitions for ML engineer resumes?
Kaggle medals demonstrate strong modeling intuition and competitive technical ability. They are especially valuable for early-career ML engineers building their track record. Include your ranking, competition name, and a brief description of your modeling approach. For senior engineers, production deployment experience and published research typically carry more weight than competition results.
Should I include GPU infrastructure experience on my resume?
GPU and distributed computing expertise is highly valued for ML engineering roles. Describe experience with multi-GPU training setups, distributed training frameworks like DeepSpeed, and cloud GPU instance management. Include specific details like training cluster configurations, training time optimizations, and cost management strategies. This infrastructure knowledge differentiates ML engineers from researchers who train models on single machines.
How do I describe model optimization work effectively?
Specify the optimization technique such as quantization, pruning, knowledge distillation, or architecture search and quantify the improvement in model size, inference speed, or memory footprint. For example, state that you applied INT8 quantization and layer pruning to reduce model size by seventy percent while maintaining ninety-eight percent of original accuracy. Connect optimization work to business outcomes like reduced serving costs or faster user experiences.
Related Resume Guides
Data Scientist
Build a compelling data scientist resume that demonstrates your statistical modeling expertise, machine learning proficiency, and ability to translate complex data insights into measurable business outcomes.
Software Engineer
Craft a compelling software engineer resume that highlights your technical depth, system design expertise, and measurable contributions to production software used by millions of users worldwide.
Data Engineer
Create a compelling data engineer resume that showcases your expertise in building scalable data pipelines, designing warehouse architectures, and enabling reliable analytics at petabyte scale.
Cloud Engineer
Create a powerful cloud engineer resume that demonstrates your expertise in designing, deploying, and managing cloud infrastructure across AWS, Azure, or GCP with reliability and cost efficiency.
Solutions Architect
Build a compelling solutions architect resume that demonstrates your ability to design scalable system architectures, align technical solutions with business requirements, and lead enterprise-level technology transformations.